Celery never retries your tasks, unless you tell it to. Here is how you can tell her to:
In this post
The Basics
There are a few basic terms and procedures that you need to know about Celery, to understand this article. All of them can be found here:
Celery: A few gotchas explained
All available settings
Here is a list of everything you can set and unset to change the retry-behavior of Celery.
All the retry-related settings:
default_retry_delay: number of seconds to wait before the next retry.max_retries: the number of times to retry, the default is 3. If this is set to 5, then the task will run up to 6 times: the first time + 5 retries.autoretry_for: a list/tuple of exceptions. When one of these exceptions occurs, the task will be retried. If a different exception occurs, the task will NOT be retried.retry_backoff: eitherTrueor an integer. When this is set, it makes sure that the interval between retries is increasing after every attempt. The number represents the number of seconds to wait until the next retry, the backoff is calculated like this \(retry\_backoff * 2^{retry}\) .retry_backoff_max: the max value for the number of minutes to wait between retries. This exists to curb the exponential growth ofretry_backoff.retry_jitter: isTrueorFalse. It is used only together withretry_backoff. If this is set toTrue, then the number of seconds to wait between retries will be randomly chosen on the interval between 0 and the number thatretry_backoffproduces:new_num_of_seconds = random.randrange(num_of_seconds + 1).
How it works
By default, Celery executes each task only once. Retrying is fully supported, but it has to be manually triggered (my_task.retry()) or explicitly setup.
1. A retry is triggered.
A new ETA is calculated. The ETA can be explicitly provided in the retry command: my_task.retry(countdown=..) or my_Task.retry(eta=..) or it will be calculated from the settings of the task. After this, the task is assigned to the same worker as has executed the task last time and is then put into the ETA queue. This queue is not really a queue, but more an ordered list of tasks with ETA. Each worker has a list like that (if there are any ETA tasks, of course). In the broker, this list is stored under the key unacked.
To inspect this queue in Redis, call:
redis-cli HGETALL unacked
2. The ETA time arrives
The task will still need to wait for its worker to have free processes/threads to execute it. This means that there can sometimes be a big difference between the ETA time and the actual execution start. You might want to keep an eye on that difference. The way we did it is that we:
-
Hook into the
task_prerunsignal to set the execution start time. This signal is rung just before the task is executed.from celery import signals, Task from datetime import datetime, timezone @signals.task_prerun.connect def task_prerun(task: Task, *args, **kwargs): """Dispatched before a task is executed. Sender is the task object being executed.""" setattr(task.request, EXEC_START, datetime.now(tz=timezone.utc).isoformat()) -
Hook into the
task_postrunsignal to send the diff between ETA and the EXEC_START time tostatsd:from celery import signals, Task from datetime import datetime, timezone from dateutil.parser import isoparse @signals.task_postrun.connect def task_postrun(task: Task, state, *args, **kwargs): exec_start_str = getattr(task.request, EXEC_START, None) eta_str = headers.get("eta") if exec_start_str and eta_str: exec_start = isoparse(getattr(task.request, EXEC_START, None)) eta = isoparse(eta_str) diff_ms = int(exec_start - eta).total_seconds() * 1000) logger.info(f"Diff between execution time and ETA is {diff_ms} ms for {task}.") statsd.timing(f"celery.task.{key}", value, tags=[f"task:{task.name}"])
3. A worker finds a free process.
The worker starts executing the task and either finishes it with the status SUCCESS (no exception and no retry occur) or FAILURE (an exception occurs, but no retry) or a new retry.
4. The max retries is reached.
If a retry is triggered, but it turns out that there are no more retries. The task’s status is set to FAILURE and MaxRetriesExceededError is raised.
Common settings
Explicit manual retry
This task will only retry if that if-statement’s body is reached. At that point the task will stop, the retry() behaves like a return statement. An ETA will be created for 30 seconds into the future. The task will be run up to 4 times: the first time + 3 retries.
@celery_app.task(default_retry_delay=30, max_retries=3)
def generate_and_send_email(user_id: int, event_name: str):
...
if something_went_wrong_temporarily:
generate_and_send_email.retry()
Retry on Exception
This task will be retried whenever either the exception EmailServerNotReachable or SomeEmailException occurs (or any of its subclasses). We could just say autoretry_for=(Exception,) and the task would retry for EVERY exception. But my experience showed me that most exceptions are not worth a task retry. Most of the time the exception that occurs will not go away with a new retry. Think of exceptions like TypeError because some code is trying to do None + 3. We can re-try this many times, but as long as something doesn’t change (the input data, the code, …), the result will end with TypeError.
After a retry is triggered, the new ETA will be set to 45 seconds into the future. The task will be run up to 6 times: the first time + 5 retries.
@celery_app.task(autoretry_for=(EmailServerNotReachable, SomeEmailException, ),default_retry_delay=45, max_retries=5)
def generate_and_send_email(user_id: int, event_name: str):
...
Retry with backoff
This scenario is especially common when we are dealing with an HTTP request in a task. We want to make the HTTP request again because we weren’t able to get data from the remote service, but we don’t want to overwhelm the remote service. To make the task user friendly, we might want to retry the HTTP request fairly soon: let’s say in 30 seconds. But if the 2nd attempt fails as well, then something bigger is probably wrong. We want to wait a bit before we ping them again: let’s say 60 seconds. If this attempt fails again, then let’s wait even longer: maybe 2 minutes. And so on. This is called an “exponential backoff”.
To set it up, you can do this:
@celery_app.task(
autoretry_for=(EmailServerNotReachable, SomeEmailException, ),
retry_backoff=30, # <- wait 30s before the 1st retry
max_retries=10,
retry_jitter=False,
)
def generate_and_send_email(user_id: int, event_name: str):
...
This task will now run up to 11 times and will exponentially increase the interval. The interval is calculated like this:
\[retry\_backoff * 2^{retry} = 30s * 2^{retry}\]After the first fail, the new ETA will be set to 30s into the future. The second time it will be 60s, the third it will be 2 mins, then 4 mins, then 8 mins and so on. I would like to emphasize again that this is an exponential backoff. It seems to me that exponential functions are so unintuitive for humans that they get us by surprise no matter how much we think we understand them.
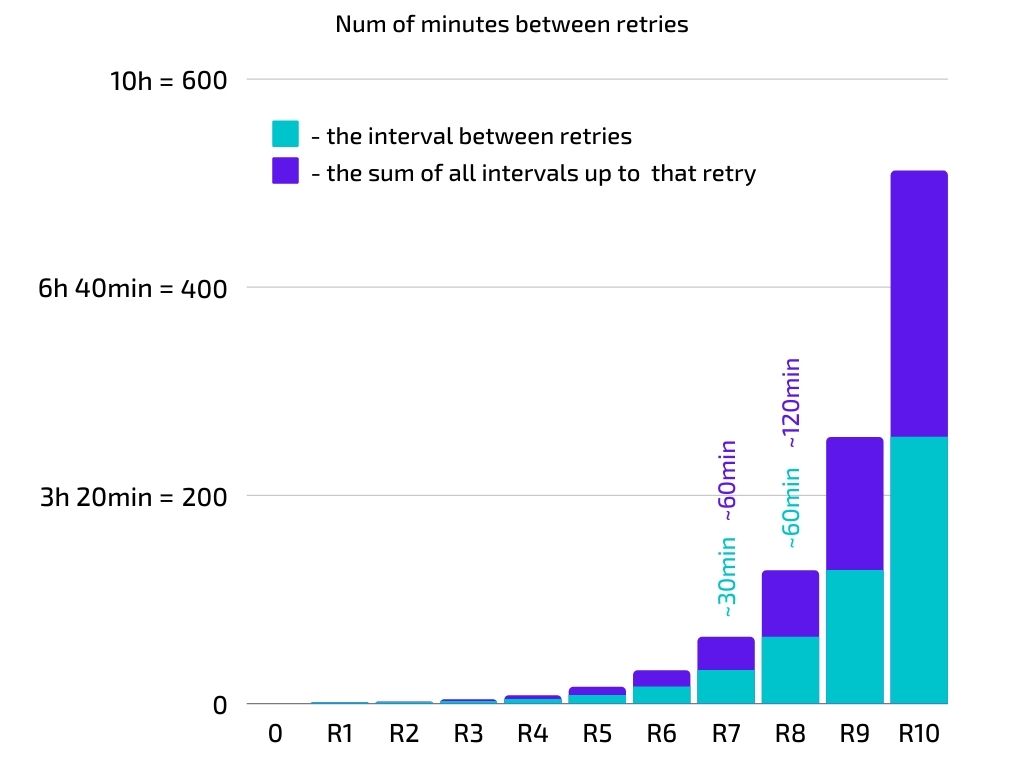
The numbers start pretty harmless, but then they grow suddenly and crazily: [30, 60, 120, 240, 480, 960, 1920, 3840, 7680, 15360]. The last number: 15360 is equal to 4h 16 min. Here is a graph of these intervals. Attention, the numbers are in minutes, not seconds, because we can visualize them better.
The green series shows how the intervals are increasing to pretty big numbers. Between retry 7 and 8, the task waits for about half an hour (=32mins=1920s) and before retries 8 and 9 it waits for about 1 hour (=64mins=3840s).
But the purple series is the real shocker. The purple series shows us how long after the task was started, is the task still running (or waiting to be run). Several hours after we started this one-off task, that task might still be running. If the task will run all 11 times, then it will only be marked as succeeded or failed after 8.5h. Or in other words, if we trigger it at around lunch, let’s say at 12:00. It will still be in the queue 6h later, at 18:00. It will only be done at 20:30 in the evening. Or in yet other words, if you are looking at the queue now, the workers might be idle, but the queue is filled with tasks that were triggered many, many hours ago. Hopefully, the users are not waiting for those results. Hopefully, you don’t have other things lined up to happen after the task is done, like… sending out a Slack notification about the event.
 Created with https://www.canva.com/
Created with https://www.canva.com/
I think most developers don’t make this calculation most of the time. And why would they, if we had stopped this task after 5 retries, the task would have completely finished after about 15 minutes + the execution time. And that seems reasonable. And very much not dangerous. But you know, a simple change of max_retries=5 to max_retries=10 gets us into trouble.
To save us, there is retry_backoff_max.
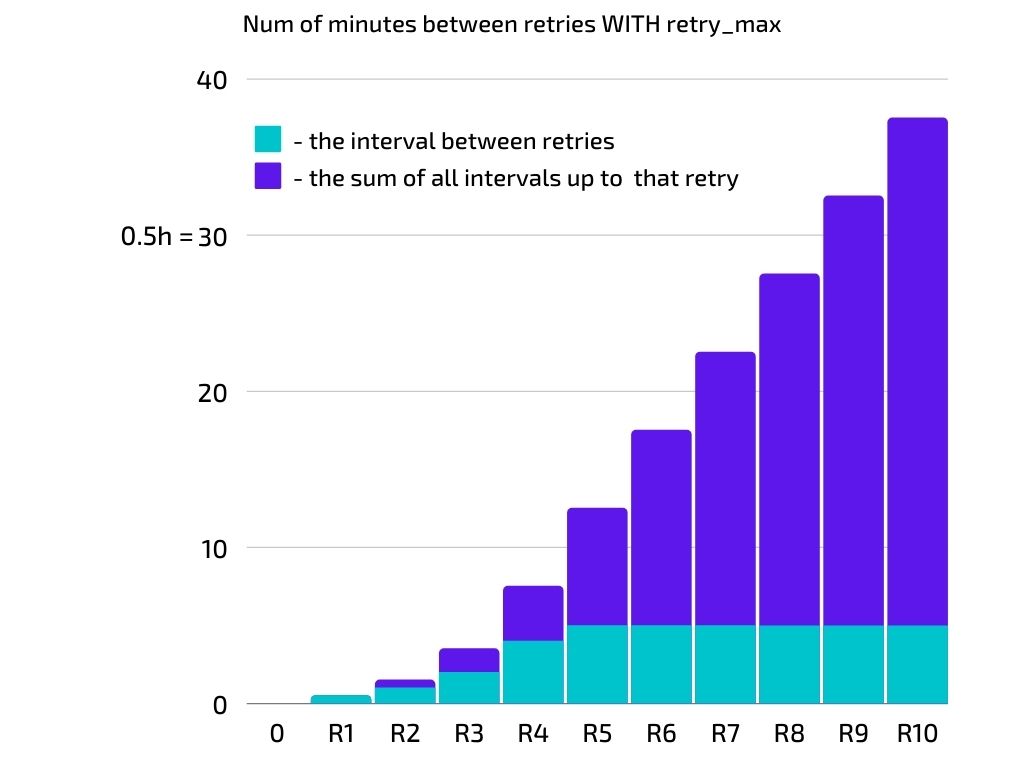
Always retry with retry_backoff_max
To avoid retry-backoff spinning out of control, use retry_backoff_max. This example limits the backoff-interval to 5 min. The intervals will go like this: [30, 60, 120, 240, 300, 300, 300, 300, 300, 300].
@celery_app.task(
autoretry_for=(EmailServerNotReachable, SomeEmailException, ),
retry_backoff=30,
max_retries=10,
retry_jitter=False,
retry_backoff_max=5*60,
)
def generate_and_send_email(user_id: int, event_name: str):
...
This completely changes the graph. Even if this task runs all 11 times, it is reasonable to expect it will be finished in less than 40mins (+ execution time).
 Created with https://www.canva.com/
Created with https://www.canva.com/
Retrying with jitter
This setting is useful for a very specific type of situation: when you have several clients starting your task at the same time. This task has an HTTP request and the task has to be retried. If all of your clients started the task at the same time, then they will all try to retry it at the same time, which is not optimal for your resources. This is where we introduce jitter. By setting retry_jitter=True, we allow randomness into the calculation of the next ETA. The next ETA won’t be the exact number as calculated by retry_backoff, instead, it will be a random number of the interval between 0 and the calculated number: random.randrange(new_num_of_seconds + 1)).
@celery_app.task(
autoretry_for=(EmailServerNotReachable, SomeEmailException, ),
retry_backoff=30,
max_retries=10,
retry_jitter=False,
retry_backoff_max=5*60,
retry_jitter=True,
)
def generate_and_send_email(user_id: int, event_name: str):
...
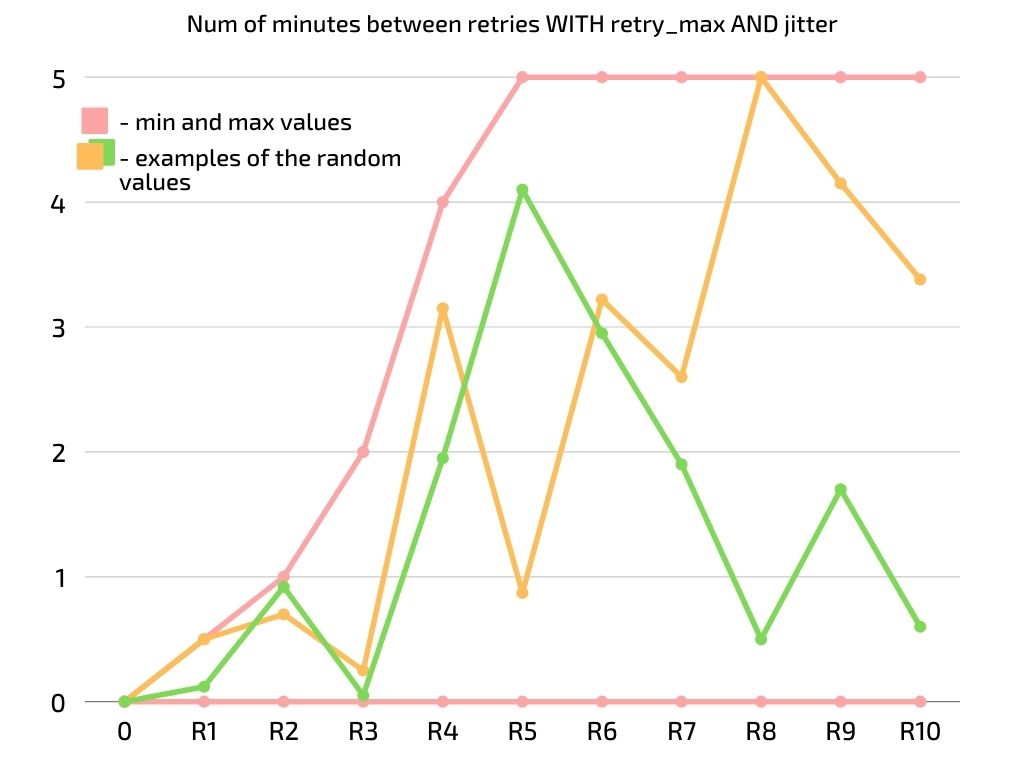
Here is a graph with the min(=0) and max(=the result of exponential backoff) “num of minutes” in light red and 2 examples of what the actual “num of minutes” will be.
 Created with https://www.canva.com/
Created with https://www.canva.com/
The jitter is only used together with exponential backoff, it has no effect next to default_retry_delay.
And here is the source code for calculating the next ETA: https://github.com/celery/celery/blob/8c5e9888ae10288ae1b2113bdce6a4a41c47354b/celery/utils/time.py#L374-L388.