In this series of posts, I wanted to create a list of stages, possible designs of a system as it caters to different-sized audiences. What is the minimum setup for a system if it has but 1 user a day and how it progresses towards a system, which serves 500M users per day.
In this post
Stage 1: 1 user
What is the minimum architecture you need for a simple website?
Let’s say you want to start a radio website called Radiodeck. You haven’t yet told this to anyone, so for now, there is going to be just you visiting Radiodeck. What is the basic system architecture for this website?
Since this is 2019, you will not host your website on your own server in the basement but will buy some server capabilities at a cloud provider (AWS, Google Cloud, Digital Ocean, … ).
The cloud provider will assign a Virtual Server to your website with a specific amount of resources (CPU, RAM, SSD, Bandwith, …) reserved for it.
You schema looks something like this:
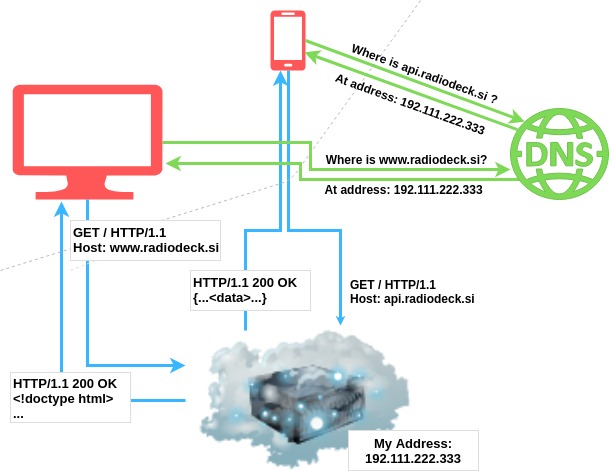
After you have registered your new domain and reserved space at the cloud provider, your IP and domain will be mapped together and stored in DNS servers. When a user types www.radiodeck.si into their browser’s URL window, their router will start the process of resolving this domain name to an IP address. Eventually, this initial request will be resolved by some DNS server.
An interesting tidbit about IP addresses: Do different subdomains have different IP addresses or the same? In our case, we have api... and www..... They can be the same or different. A domain can be registered with a wildcard *.radiodeck.si, in which case all subdomains will have the same IP and will live on the same server. In this case, the server needs to be able to distinguish between subdomains to handle them correctly.
Once the IP address is known, the actual request can take place. The browser will send an HTTP protocol request specifying what page/resource they need and will receive an HTTP response with the appropriate response.
The most common response is an HTML document. This is what is usually served to browsers for their GET requests. Mobile apps, on the other hand, most commonly receive structured data in the JSON format (or for historical reasons in the XML format).
Stage 2: 500 active users
*Generally speaking a 500 users is not much, but let’s say your Radiodeck website is somewhat memory(RAM) intensive and your visitors tend to stick on the site for a longer time.
How do you modify your system?
You have 2 options: either you scale Vertically or Horizontally. Either you buy a server with better performance, more RAM, CPU, storage, … or you buy a second server.
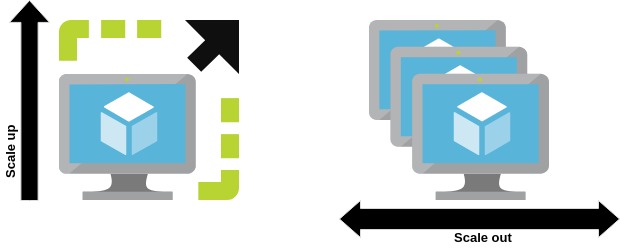
Scaling up (vertically) is generally more expensive, but it also has very hard limits. After a certain amount, you cannot get more CPU or more RAM for any price. Scaling out (horizontally) is thus usually preferred. It does demand a few code changes (or at least settings changes), but it also opens up the possibility to create redundancy more easily later on.
The easiest way to test out horizontal scaling, without having to drastically change your code or delve into the problems of distributed systems, is to put your DB on a separate server.
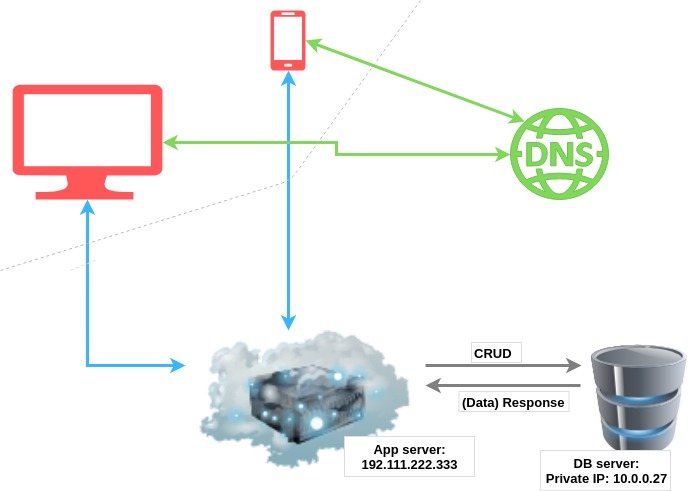
This way you have duplicated your resources for a low price. Both of your servers can now scale independently of one another. They can take care of their available resources without disturbing one another.
One downside, however, is the newly introduced latency between the 2 servers. But most of the time, this will be nothing compared to the time you are losing querying the database with bad code or non-optimized ORM calls.
Stage 3: 1000* active users
*Again, 1000 is a randomly chosen number. 1000 users can be a lot or a little, depending on your site.
Scale your App server
You are gaining in popularity (or at least you are hoping you are ![]() ). The load on your app server is getting a bit too much, what can you do next?
). The load on your app server is getting a bit too much, what can you do next?
Let’s add another app server. If one is happy handling 1000 users, two should be able to take care of 2000 users. But since we have 2 app servers now, we need to add a Load Balancer to direct the requests evenly to both.
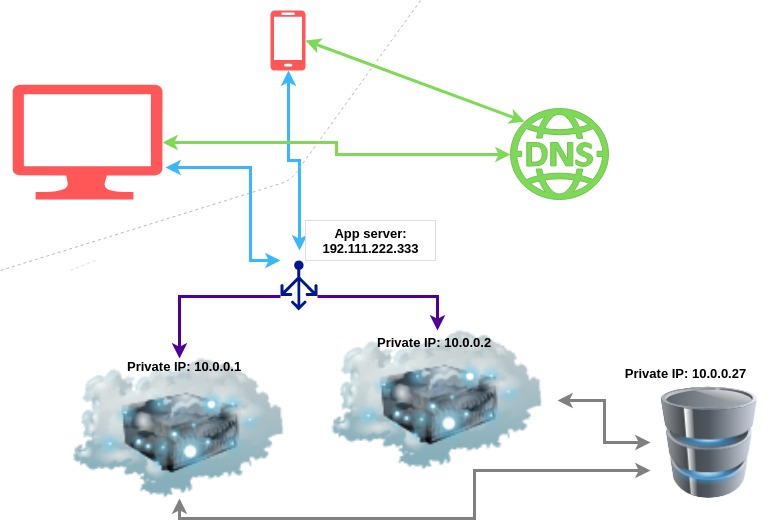
With this setup, we gain the capacity to serve more users, but we have also increased the availability of our radio. If one of the servers goes down, our website will still be available through the other one.
The IP address that is associated with our website is now used to contact the load balancer. Our servers are now reachable only on the private network. This has the added benefit of increased security. Since there are fewer components accessible publicly, there are also fewer resources to attack.
Over the years, load balancers have gained more and more responsibility and have developed into a sort of gatekeepers for the servers they “guard”. They are often used as a line of defence against DDoS attacks since they can automatically redirect suspicious requests away from your servers.
Scale your DB server
What if it is your DB server, which is struggling? With these few users, you are probably not suffering from too many writes but from too many reads. Or maybe you just want to add some redundancy on the DB side as well. If one of your app servers dies, you still have the other one, but if your DB server dies, Radiodeck does not work.
What can you do?
The first step in scaling a DB server is setting up Read Replicas. To do this, you create one or more copies of your database. Mark one of them as the “master” and the others as “slaves”. All the write actions (Create, Update, Delete) will be done on the Master DB, all the read actions will be done on the slave DBs. After every write, data is eventually synched to all slave DB servers.
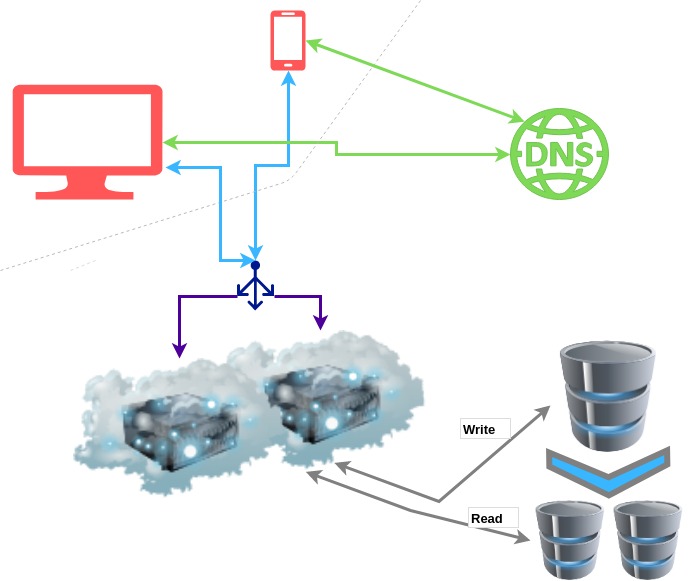
This approach has 3 main advantages:
- you can handle more requests,
- any kind of data processing (backup, analytics, reporting, …) can safely be done on one of the replicas without it affecting the performance of the website,
- if any of the servers go offline, you can replace them easily. If the master is down, one of the slave DBs is promoted to master. Whereas if one of the slaves goes down, it is usually simple to create a new slave.
Stage 4: 10 000 active users
At this many users, it is high time we introduce some serious caching. Caching will represent a sort of faster database. It will store the same information as we could have acquired by processing some information from the database, but after doing this once, we will store the result close by to have it available for the next request in need of the same information.
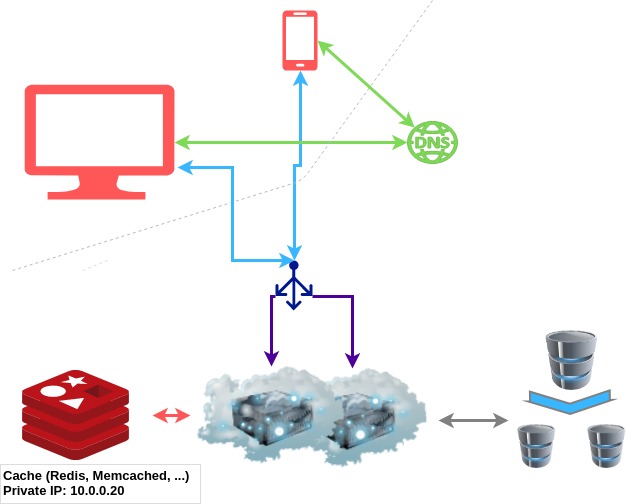
A typical cache is a simple key-value store for arbitrary data, which stores data in memory. Usually, they have a very simple API, not unlike this:
value = cache.get(key_name)
cache.set(key_name, value)
Usually, the crucial concern is how to set the TTL or “time to live” effectively. TTL defines how long you wish your value to be stored, it is usually measured in seconds.
If you set TTL too short, then you are not taking full advantage of your cache, you are forcing your servers to re-calculate data, which has not changed in the meantime. If you set your TTL too long, you might be serving old data to your users.
One interesting strategy is to set the TTL to forever and then delete the value from your cache manually after a write to your DB, which influences the cached value. But this means you need to hold a mapping of which DB rows influence the values of which key.
A permutation of this technique is to bake the TTL value into the key name. Let’s say you want to cache the last 10 news articles. You could build your key as news_<datetime_of_last_change>. But this means that every time you wish to use the cache, you must first ask the database for the datetime_of_last_change.
Another problem is data consistency. When scaling across multiple regions, maintaining consistency between cache servers and the database servers becomes a challenge.
Stage 4: 100 000 active users
Part 2 of the series: Scale your system Part 2 (From 100 000 to 100 million users)
External sources
- System Design Interview - An insider's guide
- Introduction to System Architecture Design
- Udacity: Web Development
- What is domain name resolution?
- IP Addresses for Domains and their Subdomains the same?
- When should one consider having a separate database server?
- Database Network Latency
- Denial of Service Attack Mitigation on AWS
- What is Memcached
- Scaling Memcache at Facebook