Very recently I stumbled upon a new and curious solution to a very minor, but very annoying problem that I occasionally bump into with PostgreSQL. Admittedly, a perfectly adequate solution already exists for this problem and Postgres’s limitations of the GROUP BY-logic, which are causing this problem make perfect sense to me and I support them fully. But (and doesn’t every rule always trigger a “but can you make an exception this time”), I never liked that solution, because it is so verbose and difficult to read. Is there a better way?
In this post
How to select additional columns when using GROUP BY together with MAX/MIN
(For the purposes of this story, ) I am a wildlife researcher and I count how many animals live where. I also have a small Postgres table, where I record the number of animals I’ve counted. Here it is:
| animal_id | num_of_animals | area |
|---|---|---|
| 1 | 120 | A |
| 1 | 80 | B |
| 1 | 10 | C |
| 2 | 50 | A |
| … | … | … |
And now somebody asks me: “For every animal, can you tell me which area they prefer?”.
Ok, I can do it. I need to GROUP BY animal_id and call MAX(num_of_animals):
select
animal_id,
MAX(num_of_animals) as max_num
from
animals
group by
animal_id
But how do I get the area? How do I get the value of the area column, in the same row as the MAX(...) is found?
I can’t just add , area_code to the list of SELECT columns, because I will get the error: column "animals.area_code" must appear in the GROUP BY clause or be used in an aggregate function. And this makes sense, but unfortunatelly no aggregate function exists that could do what I want it to. I don’t want to know the MAX(area_code), nor the COUNT(area_code), I want to know something like this SAME_ROW_VALUE(area_code, column=max_num).
The standard solution (and possibly the fastest, most optimized and most boring solution of them all)
One of the standard solutions is to use a subquery: we INNER JOIN the 1st query with the animals table to identify the rows where the animal_id and max_num match:
select
animals.animal_id,
max_num,
area_code
from
animals
inner join (
select
animal_id,
MAX(num_of_animals) as max_num
from
animals
group by
animal_id) as max_num_of_animals
on
animals.animal_id = max_num_of_animals.animal_id
and animals.num_of_animals = max_num_of_animals.max_num
Let me be honest here, if you have a huge table with lots of data and you care about speed, then you should first profile the results of this solution. Chances are this on is perfectly adequate, maybe even awesome, but to paraphrase my (usually very soft spoken) friend: “PROFILE YOUR QUERIES ON YOUR ACTUAL DATA before making a decision”.
But, if this long-winded letter of a SELECT-statement irks you out, let me introduce you to other, more funky solutions 😏.
My favorite solution (very hacky, but so short)
Here is the solution I like better. I’d like to emphasize I am not the author of the idea, I am just spreading the word. I found this solution in a StackOverflow post, but I don’t know which one and I’ve just spent half an hour searching StackOverflow for it with no luck.
So, here is my favorite solution.
select
animal_id,
MAX(num_of_animals),
SUBSTRING(MAX(CONCAT(to_char(num_of_animals, '0000000000'), area_code)), 12) AS "area_code"
from
animals
group by
animal_id
I know, that additional SUBSTRING(MAX..... demands some explanation. 😁
to_char(num_of_animals, '0000000000'): we turnnum_of_animalsinto a string with zeros at the begining like so:0000000120,0000000080, .. The string0000000000must have as many zeros as the biggestnum_of_animalscan have digits.CONCAT(..., area_code): we append the area_code to the back like so:0000000120A,0000000080B, …MAX(..): we find the maximum values of these strings. Because the strings start withnum_of_animals, their MAX will be the same as the MAX ofnum_of_animals.SUBSTRING(..): we strip away zeros and thenum_of_valuesto get only thearea_code:SUBSTRING(0000000120A, 12) => A. ATTENTION:to_charcreates white space at the beginning of the string, so we have to subtract 12 chars, not just 10.
I personally, like this approach, but again “PROFILE YOUR QUERIES ON YOUR ACTUAL DATA before making a decision”. It all depends on your data, the size of your table, the data types of your columns, your hardware, …
My friend’s solution (because “the above solution is so hacky, that it should only be used in the context of MySQL” :P - hat tip to MySQL for being the most popular database platform)
SELECT
DISTINCT animal_id,
first_value(area_code_2) OVER win AS area_code,
first_value(num_of_animals) OVER win AS num_of_animals
FROM
animals
WINDOW win AS (
PARTITION BY animal_id
ORDER BY
num_of_animals DESC)
This one is definitely very sleek and concise, but demands more advanced knowledge, because it replaces GROUP BY with a window function. Here is how it works.
We start with a very simple, self-explanatory SELECT statement: select distinct animal_id from animals.
Then we add a window functions, for which Postgres uses the name PARTITIONs. Window functions do 2 things: first they create a subset of the table rows and then they perform some calculation on the subset. It is important to note that a different subset is created for every row of the original SELECT statement. In our case, the window will always hold all the rows that have the same animal_id as is the animal_id in the original SELECT (=PARTITION BY animal_id). And the calculation in our case is first_value(num_of_values), so the num_of_values from the first row in the window subset.
This is what window functions will see in our case:
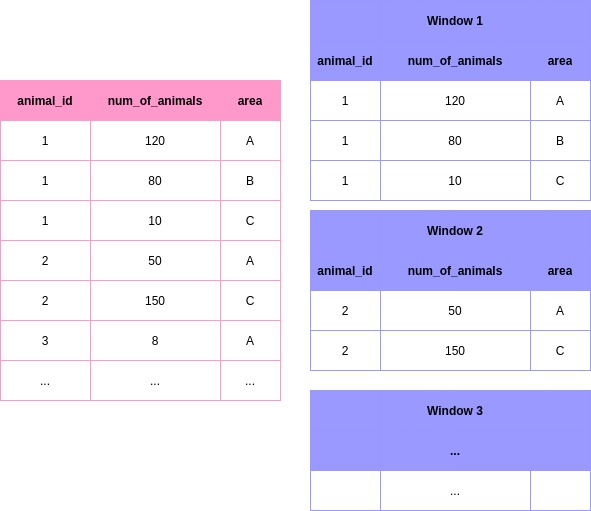
Because we also order the values in each partition (=ORDER BY num_of_animals DESC), the first row will always be the one we want.
This is it, 3 quite different ways to get the same data from the DB.
And this is is as good a proof as any that programming is a weird combination of precise machine manipulations and free-style art creation.